Architecture overview
They say a picture speaks a thousand words. So to understand how we aim to achieve a high availability and resilience to (machine/operator) failure, please review this diagram: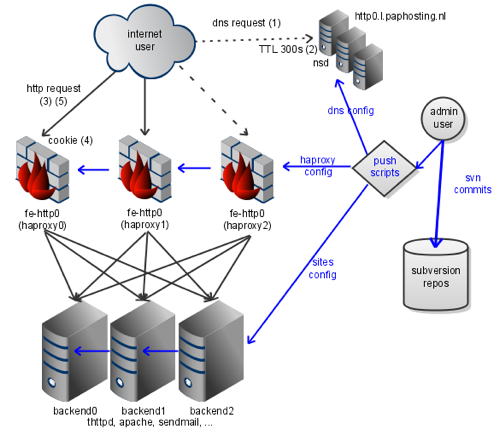
The flow of configuration and website data is depicted in blue arrows. The flow of user requests is shown as black arrows. The admin user configures things from a client on his workstation. When his configuration or site changes are reviewed, he submits them to an RCS (revision control system). In our case, this is a subversion server (this is the hard disk icon at bottom right). They then run push scripts to validate and copy the configuration to a set of servers.
Server Architecture
This diagram shows three server types:- haproxy - shown in the middel as firewall icons. These are configured identically, and have one or more frontend settings (for example, fe-http0). They are also aware of one or more backend servers, see below.
- webservers - shown at bottom center as computer icons. These are running in our case either apache or thttpd, and they are also configured identically (that is to say, they all have all the content associated with our websites, such as www.paphosting.nl).
- nameservers - shown at the top right as computer icons. They run nsd, and they are configured identically (they are all configured as master nameservers). They serve (amongst others) the zone l.paphosting.nl and decide which haproxy addresses are served to users.
Request Flow
The request flow for users on the internet (depicted in the proverbial cloud) is as follows, note the numbers in parentheses in the diagram which depict where a special trick is used:- The user issues a DNS request for http0.l.paphosting.nl (generally to their ISPs resolver). If their ISPs resolver does not know about this request, it'll forward it eventually to one of our authoritative nameservers.
- Our authoritative nameservers look up in their local zonefile which of the set of possible haproxy machines we want to use. It will give out a response with a time to live (TTL) of 300s, which the client will use. This forces the client to check back with our nameservers relatively frequently.
- The client creates an HTTP request to the haproxy, the one it was told to use by our nameserver. When the haproxy receives it, it will pick one of the backends using a configuration file. All the time, it is health checking its backends, and will chose one which is up and willing to serve, and forward the request.
- The webserver does its thing and relays the HTTP response to the haproxy. On the way out, the haproxy will annotate the response with a cookie, containing the address of the webserver it chose earlier. Incidentally, for stateless services this is not relevant (and not enabled), but for stateful services, it can be very important for this session persistence to work.
- Most modern browsers will start issuing this cookie in subsequent requests. This enables any of the haproxy machines (even ones that have never seen this client before!), to chose the same backend deterministically. This allows most stateful services to stick on the same backend.
Common Failuremodes
If one of the haproxy machines becomes unavailable, the operator can update the DNS to avoid giving out that machine's address. Voilà, DNS can be used to enhance site stability and work around a broken haproxy, our primary line of defense.The haproxy machines health check their backends (by issuing HTTP requests to them every N seconds). If several of those requests fail, or time out, the backend is marked bad and not selected for any new requests. If we lose a backend for a stateless service, we suffer no adverse effects. If we lose one for a stateful service, haproxy is configured to fail over permanently to a backup backend (that is to say, in normal operation, the primary backend is used for all requests, but if it fails, we can fall back to another backend).
Nameserver machine failure is not generally a problem. Resolvers know how to work around transient DNS failures and will try one of the other authoritative nameservers they know of. Most modern resolvers will deselect broken nameservers automatically, and periodically retry them to see if they are back up.
Subversion repository server failure is not noticable by end users. If the operator wishes, he can choose to work from his client and defer submissions to the repository. All push scripts work from two or more admin machines, so admin machine failure is not an issue. Particularly so, because one of the admin machines is in The Netherlands, and the other is in Switzerland, and both are in different ISP networks.